KFL&A Public Health and its response to COVID-19.
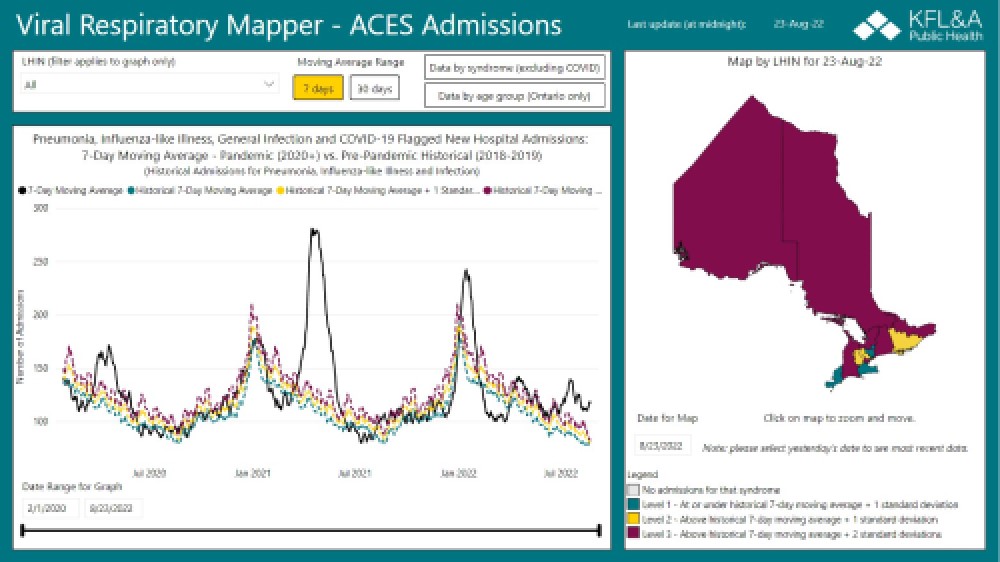
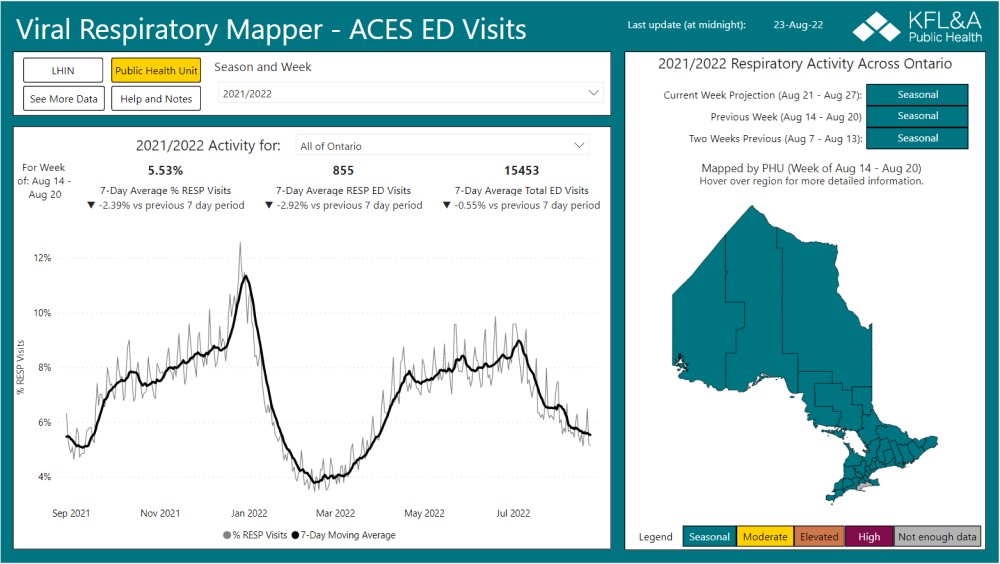
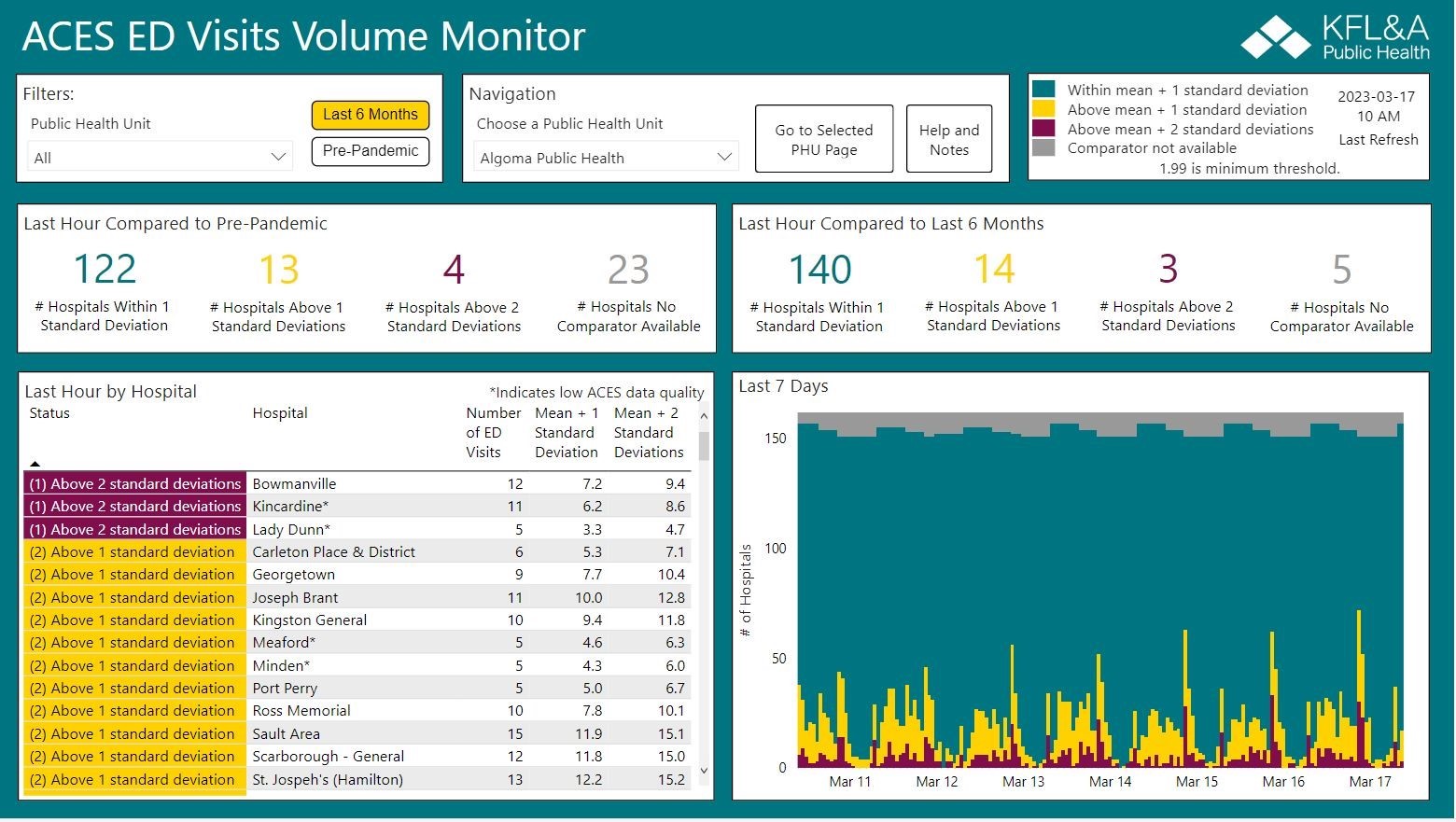
ACES: Acute Care Enhanced Surveillance
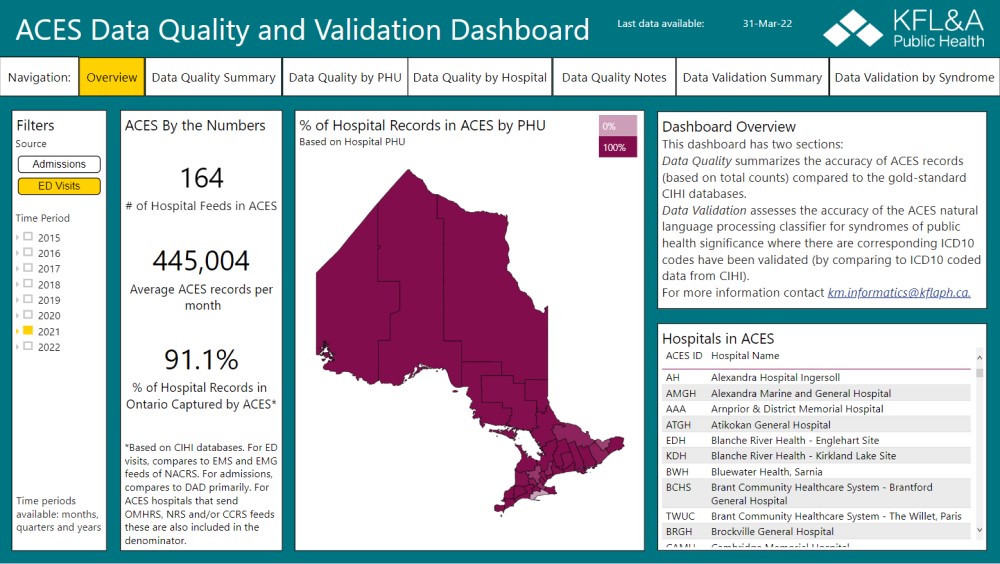
ACES provides real-time epidemiological surveillance for Ontario. The application is for registered users only, but several ACES data products are available here.
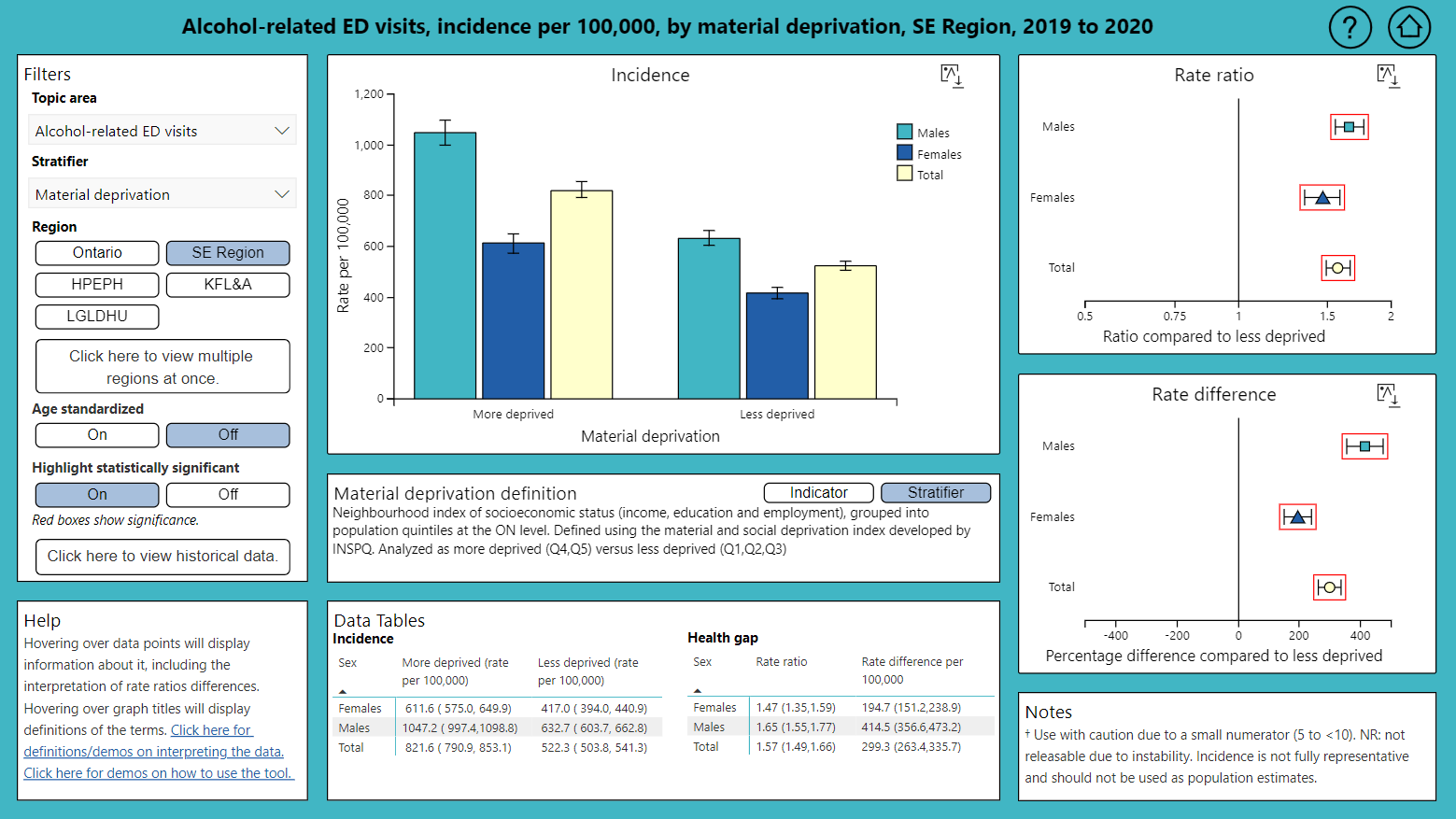
SHED: Shared Health Equity Dashboard
The Shared Health Equity Dashboard (SHED) is a collaboration between three local public health agencies in southeastern Ontario. Its purpose is to allow users to interact with population health data to identify gaps in health between groups of people defined by certain social characteristics.